CentOS8上安装与配置Hadoop3.3测试环境
大数据必备基础软件之hadoop安装
1、建立3台虚拟机,分别为masterNode,node1,node2。(建设虚拟机可自行查找相关文章,本文用的VirtualBox)
2、同步虚拟机时间
CentOS8中已经不在使用ntp服务来进行时间,更新为chrony。
#安装chrony包
dnf install chrony -y
#修改配置文件
vim /etc/chrony.conf
在第一行新增下边内容后,:wq保存退出
server ntp.aliyun.com iburst
#重启服务
systemctl restart chronyd
#再次查看系统时间已经同步(如果内同步,请等几秒再看)
date
3、配置hostname,分别为master、node1、node2
vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=master(此处改为对应机器的节点名)
4、配置hosts
vi /etc/hosts
#127.0.0.1 localhost
#::1 localhost
192.168.3.27 master
192.168.3.28 node1
192.168.3.29 node2
ip地址为各节点服务器地址,使用ip addr命令查询即可
5、关闭防火墙(否则管理网页打不开)
systemctl stop firewalld.service
systemctl disable firewalld.service
6、安装JDK
以下方式都可以安装:
1)、rpm包安装(本实验用此方式)
去java.oracle.com下载jdk1.8版本rpm安装包
rpm -i java.rpm(此处为下载的对应jdk版本安装包)
2)yum安装
yum install java-1.8.0-openjdk
配置环境变量
vi /etc/profile
末尾追加
export JAVA_HOME=/usr/java/jdk1.8.0
export JAVA_BIN=/usr/java/jdk1.8.0/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/jre/lib/rt.jar
export PATH=$PATH:$JAVA_HOME/bin
使环境变量生效
source /etc/profile
#查看JDK是否安装成功,注意,是java -version,不是java --version,1.8已经变更为单横线
java -version
7、创建hadoop用户
useradd hadoop
修改密码:passwd hadoop 设置为123123
8、配置ssh无密钥证书(重要,保证节点间的免密访问)
[hadoop@masterNode ~]$ ssh-keygen -t rsa
[hadoop@masterNode ~]$ ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub masterNode
[hadoop@masterNode ~]$ ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub node1
[hadoop@masterNode ~]$ ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub node2
以上步骤在每个虚拟机都要执行
9、hadoop安装
去官网下载tar包解压,找对应的镜像网站下载即可,地址:https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
解压安装包 tar -zxvf hadoop-3.3.0.tar.gz
创建dfs相关目录
[hadoop@master hadoop-3.3.0]$ mkdir -p dfs/name
[hadoop@master hadoop-3.3.0]$ mkdir -p dfs/data
[hadoop@master hadoop-3.3.0]$ mkdir -p dfs/namesecondary
进入hadoop配置文件目录开始进行参数配置
cd /home/hadoop/hadoop-3.3.0/etc/hadoop
修改配置文件core-site.xml,详细参数请参考http://hadoop.apache.org/docs/r3.3.0/hadoop-project-dist/hadoop-common/core-default.xml
<configuration></configuration>中增加如下内容
[hadoop@master hadoop]$ vi core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
<description>NameNode URI.</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
<description>Size of read/write buffer used inSequenceFiles.</description>
</property>
修改配置文件hdfs-site.xml,详细参数请参考:http://hadoop.apache.org/docs/r3.3.0/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
<configuration></configuration>中增加如下内容
[hadoop@master hadoop]$ vi hdfs-site.xml
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
<description>The secondary namenode http server address andport.</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/hadoop/hadoop-3.3.0/dfs/name</value>
<description>Path on the local filesystem where the NameNodestores the namespace and transactions logs persistently.</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/hadoop/hadoop-3.3.0/dfs/data</value>
<description>Comma separated list of paths on the local filesystemof a DataNode where it should store its blocks.</description>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///home/hadoop/hadoop-3.3.0/dfs/namesecondary</value>
<description>Determines where on the local filesystem the DFSsecondary name node should store the temporary images to merge. If this is acomma-delimited list of directories then the image is replicated in all of thedirectories for redundancy.</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
修改配置文件mapred-site.xml,详细参数请参考:http://hadoop.apache.org/docs/r3.3.0/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
<configuration></configuration>中增加如下内容
[hadoop@master hadoop]$ vi mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>Theruntime framework for executing MapReduce jobs. Can be one of local, classic oryarn.</description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
<description>MapReduce JobHistoryServer IPC host:port</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
<description>MapReduce JobHistoryServer Web UI host:port</description>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/opt/hadoop-3.3.0/etc/hadoop,
/opt/hadoop-3.3.0/share/hadoop/common/*,
/opt/hadoop-3.3.0/share/hadoop/common/lib/*,
/opt/hadoop-3.3.0/share/hadoop/hdfs/*,
/opt/hadoop-3.3.0/share/hadoop/hdfs/lib/*,
/opt/hadoop-3.3.0/share/hadoop/mapreduce/*,
/opt/hadoop-3.3.0/share/hadoop/mapreduce/lib/*,
/opt/hadoop-3.3.0/share/hadoop/yarn/*,
/opt/hadoop-3.3.0/share/hadoop/yarn/lib/*
</value>
</property>
修改配置文件yarn-site.xml,详细参数请参考:http://hadoop.apache.org/docs/r3.3.0/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
<configuration></configuration>中增加如下内容
[hadoop@master hadoop]$ vi yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
<description>The hostname of theRM.</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>Shuffle service that needs to be set for Map Reduceapplications.</description>
</property>
修改配置文件 hadoop-env.sh
末尾追加
[hadoop@master hadoop]$ vi hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0
修改配置文件workers
[hadoop@master hadoop]$ vi workers
node1
node2
复制hadoop3.3.0目录到另外两个节点
[hadoop@master ~]$ scp -r /home/hadoop/hadoop-3.3.0 hadoop@node1:/home/hadoop/
[hadoop@master ~]$ scp -r /home/hadoop/hadoop-3.3.0 hadoop@node2:/home/hadoop/
切换用户到root账户,将hadoop加入到环境变量中
[root@master ~]$ vi /etc/profile
PATH=$PATH:$HOME/bin
export HADOOP_HOME=/home/hadoop/hadoop-3.3.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
使环境变量生效
source /etc/profile
切换回hadoop用户
格式化namenode
[hadoop@master ~]$ hadoop namenode -format
启动hadoop
[hadoop@master ~]$ start-all.sh
10、hadoop验证
进程验证
Master节点验证
[hadoop@master ~]$ jps
3167 NameNode
5258 Jps
3346 SecondaryNameNode
3560 ResourceManager
Node节点验证(node1、node2相同)
[hadoop@node1 ~]$ jps
2862 Jps
2744 NodeManager
2630 DataNode
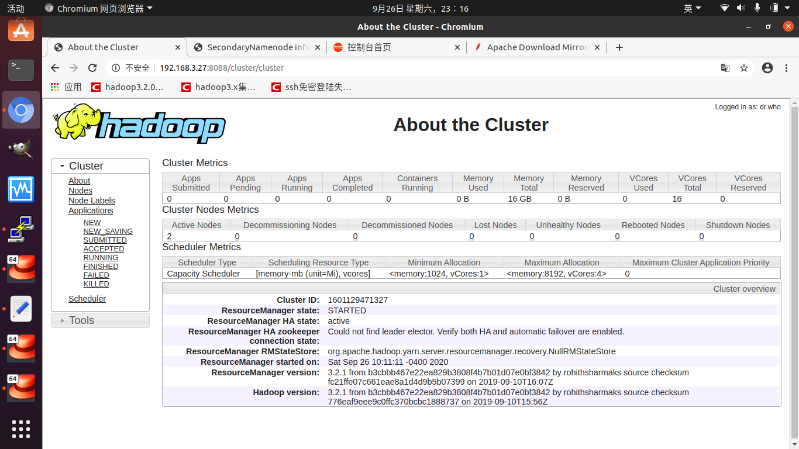
web界面验证
http://192.168.3.27:8088/
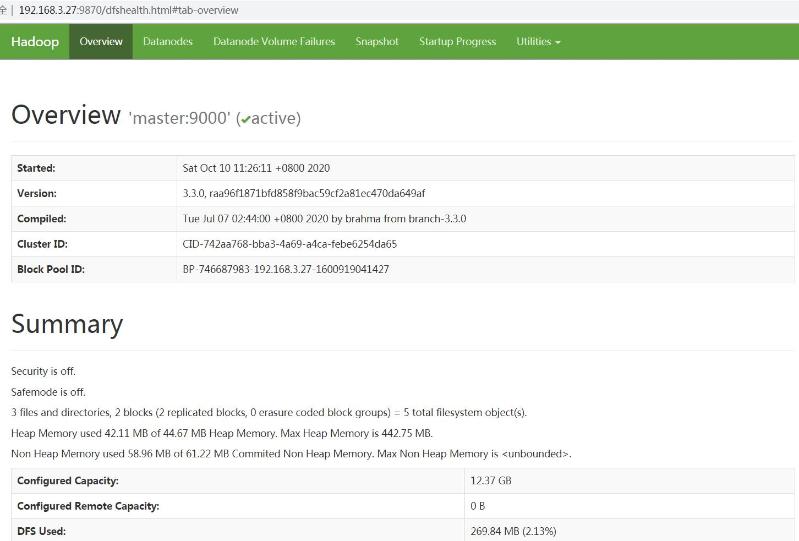
Namenode information界面
http://192.168.3.27:9870/
注意点:
1、务必关闭防火墙,否则网页是打不开的!!!
2、务必不能将hadoop用户的home文件夹权限变更为777,否则ssh无法互相访问
3、hadoop3已经将web管理页面端口从50070改为9870

